Shaking the Kinder Egg - Or: Metadata of Data Products?
Shaking the Kinder egg - or: metadata of Data Products
Who hasn’t done it? shaking the Kinder eggs to “guess” what’s inside and raise the chance of getting one of the figures. We even put them on the vegetable scale to increase the chance (many many years back the figures had higher weight than the assemble stuff). But in the end, it was all guessing.
When we deal with data, we don’t want to guess. We want to get the clearest view on “what’s inside” as possible. And with the Data Mesh approach, in with we create the Data Products to reuse existing data, this is more important than ever. But how do we do that?
First, let’s have a look on ‘What is a data product’ again. in the last post I sketched the Data Product already. It has these main elements in it:
- Infrastructure
- Code
- Input & Output Ports
- Control Port
Ideally, everything what is done is code based, including setting up the infrastructure (infrastructure as code), data transformation steps etc.
The required infrastructure for that data product is connected to it. Depending on the type and usage of the product, it can vary. Ususally there’re two main types:
- Batch
- Stream
The input and output ports are the connectors to the data sources (input) and to the data consumers (output). Depending on the type of data product and the data sources and uses cases, these can be regular API endpoints like jdbc, s3, kafka, mqtt, https, … .
But the more important (at least for this post) port is the Control Port. Why? Well, with this specific endpoint we get information from and control the defined data product. So let’s take an example:
As a business user In order to reuse existing data, I want to get the following information from a Data Product within my organization:
- In what domain is that data product?
- Who has created it?
- What information / fields are available?
- when was it updated last time?
- what is the data quality of it?
- what data sources is this Data Product connected to?
- what connection options I have to work with the Data Product?
And here the Control Port comes in.
This port provides a consistent view on the Data Product. Endpoints are e.g.:
- metadata {name, owner, source systems}
- lineage information
- address of ports {input, output}
- schema {input, output}. link to company ontology
- audit
- metrics, i.e.
- last updated timestamp
- loading frequency
- loading time (how long did it take to load data)
- data volume
- data quality metrics {e.g. # of unmapped records}
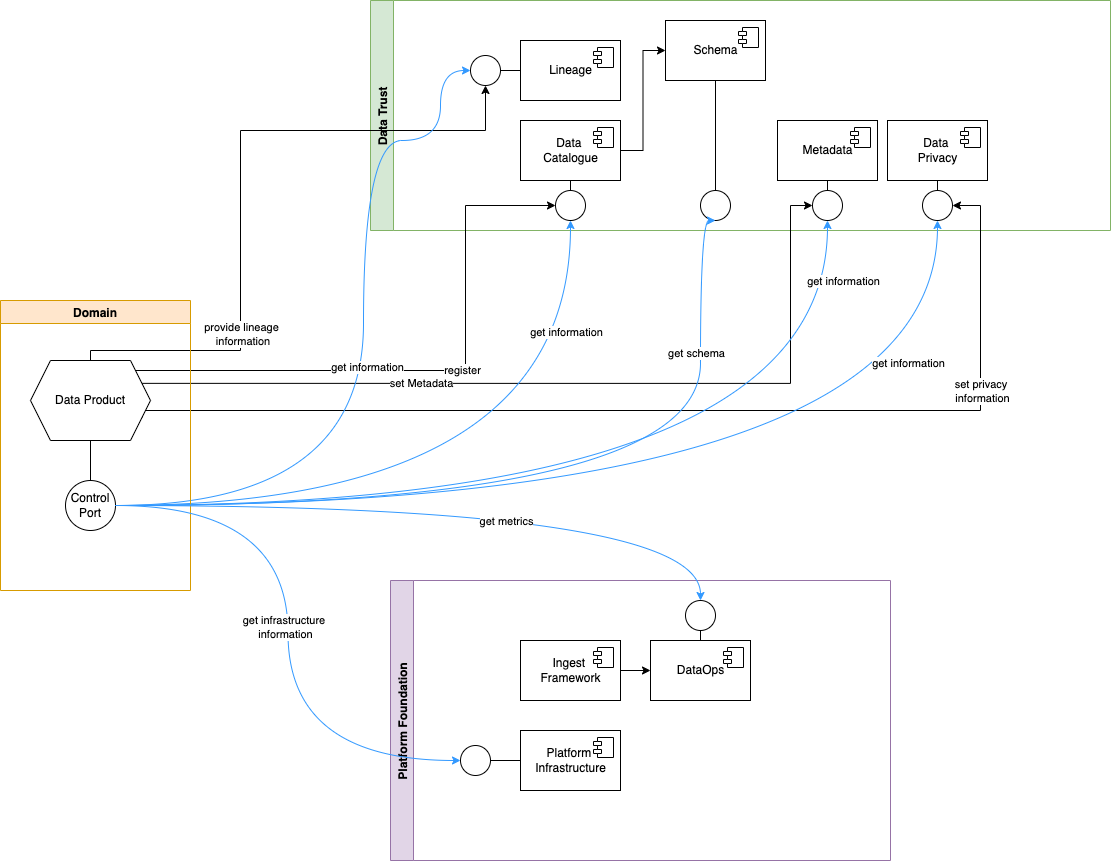
As you can see in the image above, the Control Port collects these information from a wide variety of sources like the Data Catalog, Data Quality Tool, the Data Lineage Tool or the DataOps tool of the Platform Foundation. It acts like an endpoint federation, as i.e. usually the Data Catalog tool of choise provides *
- a nice integration to publish the data product into the catalog
- an API to get information out of the catalog
Same applies (or should be applied) to the other components of the Data Trust layer.
So let’s take an example on the metrics, as these are quite common to be asked by the business in order evaluate further usage of the existing Data Product. When the business has easy access to the metrics of a Data Product, it can easily evaluate how much value this Data Product brings it for their use case(s). The exemplary metrics mentioned above give a good overview on typical demands and have their basis in the SRE Workbook.
But how does the user get these information? Do they have to query the API? Well, these information have to be available as API endpoints to allow automatic processing. But for Business Users there has to be a proper frontend incorporting them and allowing searching, visual exploration and interaction with the underlying information. This can be a custom frontend communicating with underlying API or off the shelf tools. (due to the broad landscape of these tools on the market, a separate post is required to capture that topic)
So, back to the initial question: Yes, the majority of us has found ways to increase the chance to get a rare mini figure as the surprise in the Kinder eggs. And we were creative with it. But nowadays, when we talk about finding the right Data Product(s) for the use cases, it doesn’t need shaking or a scale. In a proper Data Mesh based architecture, all the relevant information are available at the control port and consumable via an API AND a proper frontend.