Accelerating Data Product Development - Speed Up the Time to Value
When we talk about time to value in data-powered organizations, we often jump too quickly to dashboards, AI models, or the latest agentic AI solutions. But time to value does not start with the use case. It starts much earlier - with the creation of the data product that enables the use case in the first place. Time to value, in this context, means the time it takes to define, build, deploy, and operate a data product together with its consuming use case - whether that use case is a dashboard, an analytical application, or an agentic AI solution. If we want to accelerate value creation, we must minimize the time spent on data product development so teams can focus on what really matters: solving the business problem.
In previous article, I’ve already explored the broader benefits of platform engineering, as well as its importance for security and trust in the age of AI. In this post, I want to zoom in on one specific aspect: how platform engineering accelerates data product development itself.
In many client conversations today, discussions still start with technology choices: Which cloud provider? Which framework? Which database? While these are valid questions, they are rarely the most important ones - especially at the beginning. Before talking about how to implement something, we need clarity on what we are building and why. That’s why it’s useful to step back and look at the process of data product development first. Independent of tools and platforms, the lifecycle of a data product follows a clear structure:
- Define the data product
- Build and deploy it
- Run and operate it as a product Only once this flow is clear does it make sense to discuss technical implementations.
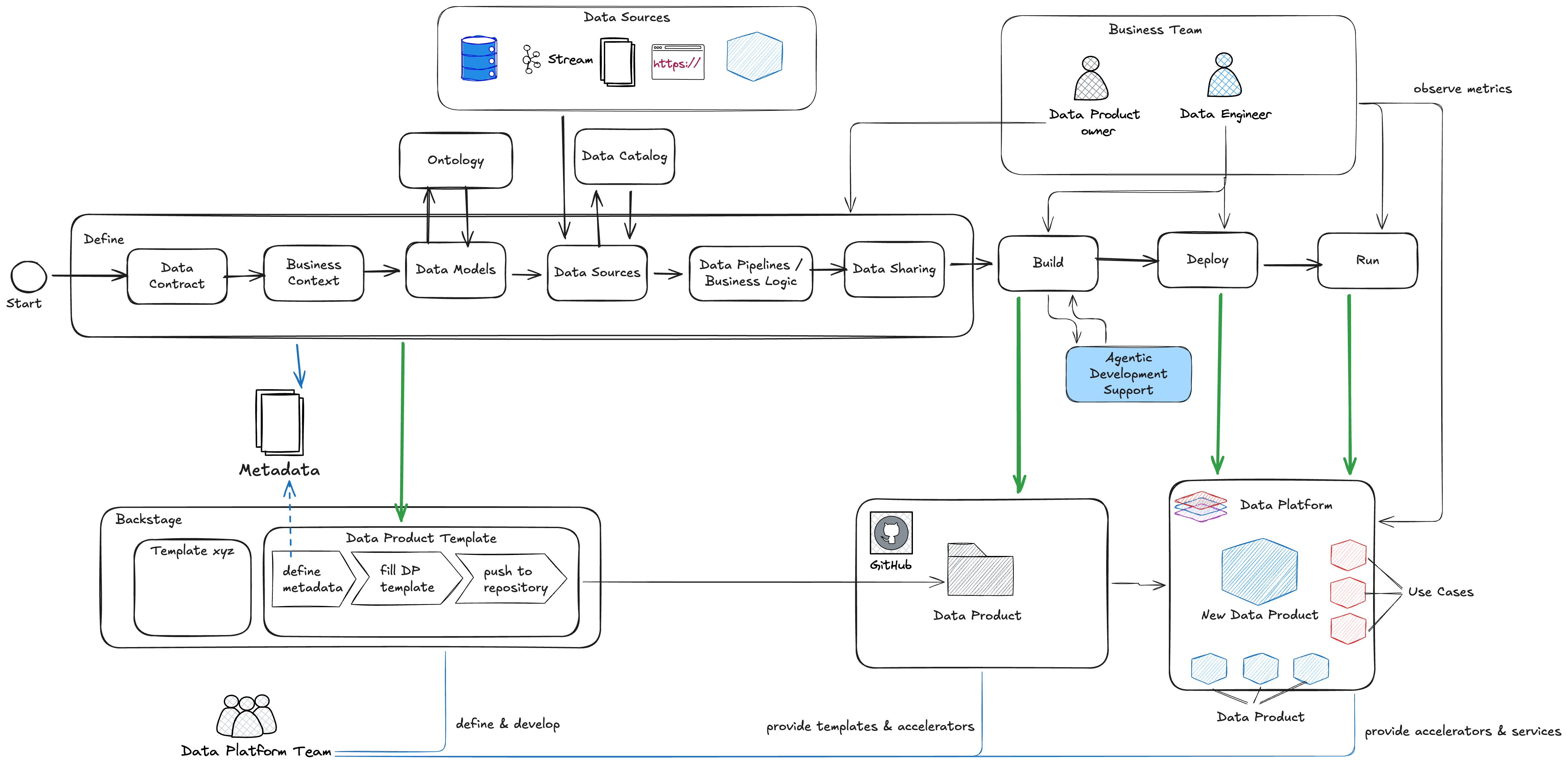
Data Product Definition - getting the foundation right
Start with the Data Contract
The first step in accelerating data product development is a clear data contract. Just like any other product, a data product needs an explicit contract to ensure everyone is aligned. A data contract typically covers:
- Ownership and accountability
- Data formats and interfaces
- Data models and semantics
- Metrics and KPIs
- SLAs and expectations This contract is not bureaucracy - it’s the fastest way to avoid misunderstandings later. It creates a shared understanding between producers and consumers from day one.
Add Business Context, Metadata and Data Model
As part of the contract, the business context is very important. It’s the context in which the data product will be used and the business problem it’s trying to solve. It’s also the context in which the data product will be evaluated and measured. That includes linking the data product to a data domain. Another important aspect we should define are the metadata we’ll later use for deciding on the quality and trustworthyness of the data product. (see a dedicated post on that matter). The Data Models is the next step and here the interaction with the company ontology pops in. But why do we need this? Semantic data products represent a piece of business understanding in a nutshell. Representing the business view for each topic, semantic data products one by one build an understanding of whole areas and enterprises. Analytics and reporting use semantic data products to focus on hotspots or aggregate the big picture. Clear technical properties in sematic data products make data from different sources available for processing in user interfaces or AI agents. Views can be generated in different scenarios and time frames that can provide insight or prediction
Input and Output Ports
A data product is not isolated. As part of its definition:
- Input ports are defined by referencing data sources via the data catalog
- Output ports define how the product is consumed and shared This explicit port concept makes dependencies visible and enables controlled reuse across the organization.
Pipelines and Complexity Awareness
Finally, we define the data pipeline where business logic is implemented. At this stage, we don’t need all details, but we should capture:
- The processing pattern
- The expected complexity
- Potential frameworks (for example, dbt for transformation logic) This helps later when industrializing and scaling the implementation.
Industrialization of that process
Defining data products well is important — but definition alone doesn’t accelerate time to value. The real acceleration comes from industrializing this process. As mentioned in the intro, to implment this process and to accelerate the actual process run, we’re using Backstage. Using Backstage as the foundation, we can turn the abstract data product process into a guided, repeatable workflow. With:
we can guide users step by step through data product definition, while simultaneously interacting with the surrounding ecosystem — catalogs, repositories, CI/CD pipelines, and more. The result is not just a form or a wizard. It’s a fully prepared repository structure that already contains:
- The data contract
- Metadata
- Semantic definitions
- Pipeline scaffolding This drastically reduces the setup time for new data products.
Accelerating the Build Phase and deploy the Data Product
Once the repository is scaffolded, something interesting happens: agentic development support suddenly becomes far more effective. Tools like Github Copilot or code-focused models such as Codestral perform best when context is rich and explicit. Because the template repository already contains:
- Business context
- Metadata
- Data models
- Contracts
code models know what they are building and why. This:
- Speeds up development
- Improves code quality
- Increases consistency
- Strengthens reuse across teams
This will not only speed up the actual data product development, but also increase reliability for the code models and strengthens the reusability within the organization.
The deployment step depends on your environment, but quite often, why not simply use Github Actions or already existing CI/CD tools for that matter. The readiness of your data product in order to release it to the multi-staged environments.
Run the Data Product - now the value of if can be leveraged
When we have deployed our data products, they’re live - on the chosen environment. End even on the DEV or TEST environment we must observe the metrics like data quality, data freshness etc.. Because that’s the point on which the data product owner can decide, if the data product is ready to be released on the PROD environment. Sounds logic? Yes, of course, but I have stopped counting how many projects I’ve seen in which clearly separated environments with enabled observability are missing and all verification and tests are actually performed on the productive environment. I don’t need to tell how fragile that construct is and how high the probability is that something breaks here.
How to accelerates the Time to Value
By combining:
- Clear data product definition
- Industrialized workflows via Internal Developer Portals like Backstage
- Agentic development support
- Standardized deployment
- Built-in observability
we drastically reduce the effort needed to create reliable data products. This allows teams to focus on use cases and outcomes, not plumbing and setup. That is how platform engineering turns data product development from a slow, bespoke process into a scalable, repeatable capability - and how organizations truly accelerate their time to value.